AI 翻译制作双语 EPUB 电子书
· 阅读需 4 分钟

 Blog
BlogEPUB Translator 保留原书版式并生成精准对齐的双语 EPUB,让跨语言阅读和学习更顺滑。
BlogEPUB Translator 保留原书版式并生成精准对齐的双语 EPUB,让跨语言阅读和学习更顺滑。
 Blog
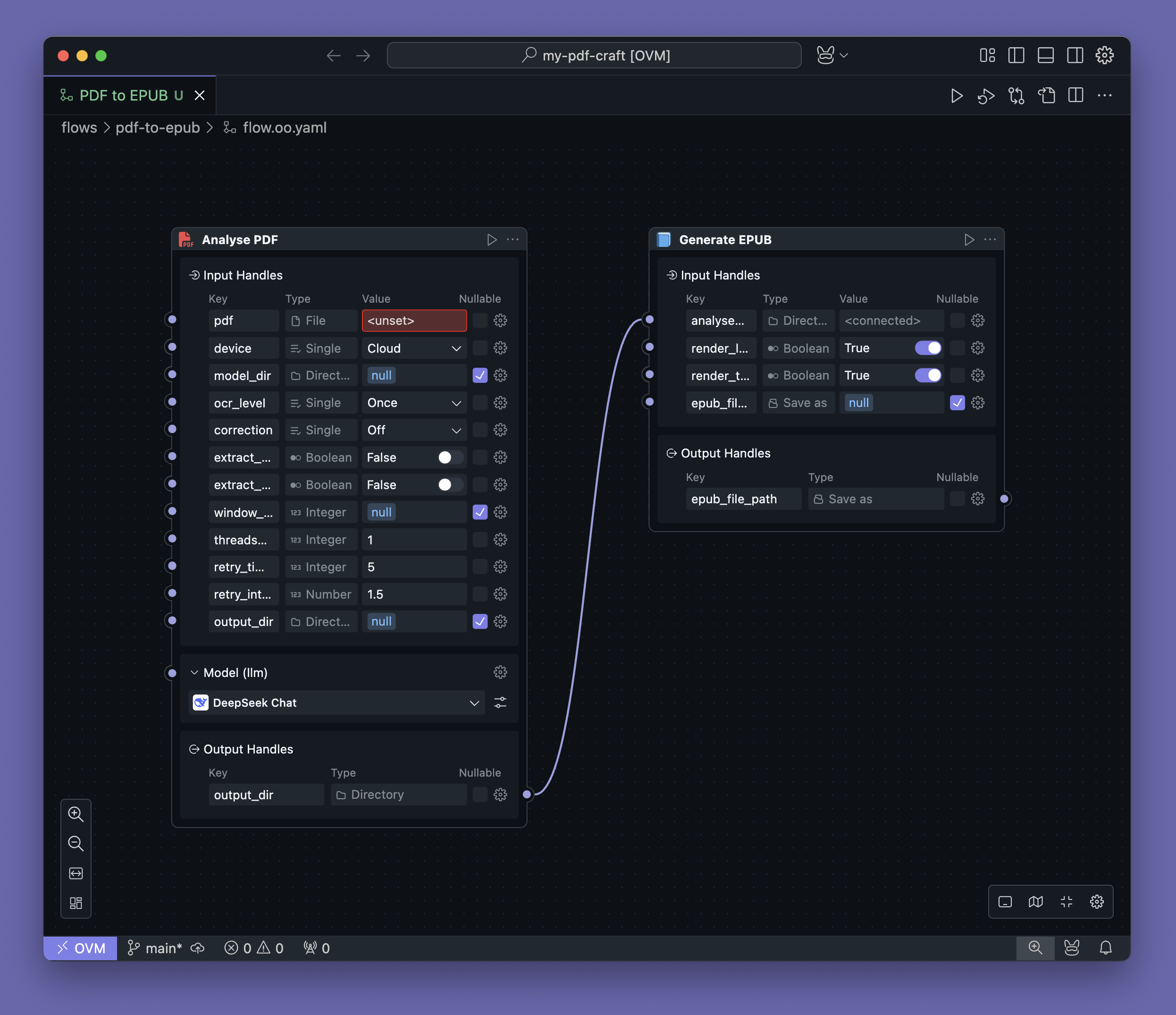
Blogpdf-craft 可将扫描版 PDF 书籍转换为结构化 EPUB,完成 OCR、阅读顺序还原和目录生成。
 Blog
Blog把真正的 Python、TypeScript 和 JavaScript 代码块直接插入 OOMOL 工作流,同时保留本地依赖和接近 IDE 的开发体验。

 Blog
Blog了解如何把 OOMOL 工作流导出成 OCI 镜像、部署成后台服务,并运行一个 PDF 转 EPUB 翻译流程。
 Blog
BlogOOMOL Studio 通过完整代码环境、本地运行、镜像导出和更完善的开发者体验,把自动化工作流工具继续往前推进了一步。